Client Background
Established in 2016, our client has rapidly emerged as a notable entity within the real estate sector, showcasing a diversified portfolio that spans commercial and residential properties across key Indian metropolises including Mumbai, Bangalore, and the National Capital Region (NCR). Leveraging the substantial land holdings of its parent conglomerate, the organization is poised for significant growth through strategic developments and collaborative ventures in major cities.
Business Objective
The client’s sales division is faced with the critical task of enhancing the efficiency and effectiveness of their pre-sales activities. A primary challenge lies in the accurate categorization of pre-sales calls into hot, warm, or cold leads, which is essential for prioritizing follow-up actions and optimizing sales strategies. Furthermore, there is a pressing need for a comprehensive analysis of call data to glean insights on sales interactions, including the assessment of the sales team’s communication skills and the identification of areas for improvement in sales pitches. Currently, the classification of leads relies solely on the subjective judgment of individual salespersons immediately following each call, which may not consistently reflect the true potential of the leads.
The organization is seeking innovative solutions to systematize the lead categorization process, enhance the quality of customer interactions, and ultimately, refine their sales approach for better conversion rates.
Scenario Planning
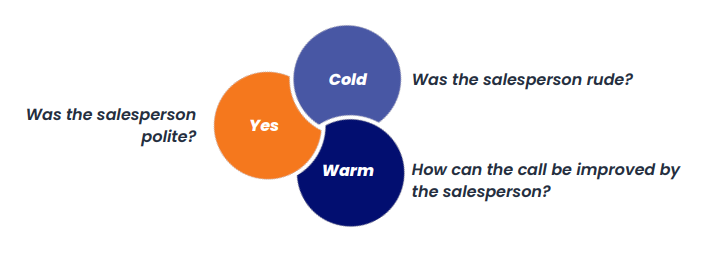
Phases in propensity modeling

Solution
Phase 1: Integration with Customer Relationship Management (CRM) System
The initial step involved the integration of the client’s call center audio recordings, stored on Amazon Web Services (AWS) S3 storage, with the CRM system. To facilitate this, a dedicated S3 bucket was established specifically for the Propensity Modeling project, ensuring a streamlined process for data handling and analysis.
Phase 2: Audio Call Transcription
Utilizing the computational power of an NVIDIA DGX A100 VM, the project team employed Python scripts to download and preprocess the audio call recordings. The preprocessing included several critical steps to ensure data quality and relevance:
- Data Sanity Checks: Brief calls, lasting less than a minute, were excluded from analysis to focus on more substantive interactions
- Voice Activity Detection (VAD): A sophisticated deep learning model was applied to filter out irrelevant audio segments, such as ring tones and filler words, enhancing the clarity and focus of the data
- Speech to Text (STT) Conversion: The refined audio data was then processed through OpenAI’s Whisper large-v3 model for speech-to-text conversion. This model was selected for its superior performance across multiple languages, including English, Hindi, Kannada, and Marathi, among others, making it well-suited for the diverse linguistic landscape of the target market.
Phase 3: Analyzing Conversion Propensity
The transcripts generated from the STT process were analyzed using Azure’s OpenAI Language Learning Models (LLMs) through an API. This phase involved extensive testing with various prompts to determine the most effective approach for predicting the likelihood of lead conversion. The finalized prompt, coupled with continuous feedback mechanisms involving business insights, enabled the dynamic refinement of the GPT model for improved accuracy and relevance.
Value Proposition
This innovative solution leverages the cutting-edge capabilities of OpenAI’s Language Learning Models to transform raw audio calls into insightful dialogues between salespersons and potential customers. By categorizing these interactions into hot, warm, or cold leads, complete with scores and reasons for categorization, the system offers a robust framework for prioritizing sales efforts and enhancing conversion rates. The use of Microsoft Azure’s OpenAI Cognitive Studio further enriches this process by providing a versatile platform for experimenting with different language models, including the latest GPT 3.5 Turbo, ensuring scalability and cost-effectiveness tailored to the project’s specific needs.
Outcome
- Achieved human-equivalent accuracy on the training dataset.
- Successfully processed calls with audio quality that challenges human comprehension.
- Preliminary evaluation of 100 calls showed very promising results
- Plans for a production phase include:
-
- Implementing a feedback system for continuous model optimization.
- Experimenting with multiple models to enhance performance.
- Developing a business dashboard for real-time metrics and insights.
-